Intro
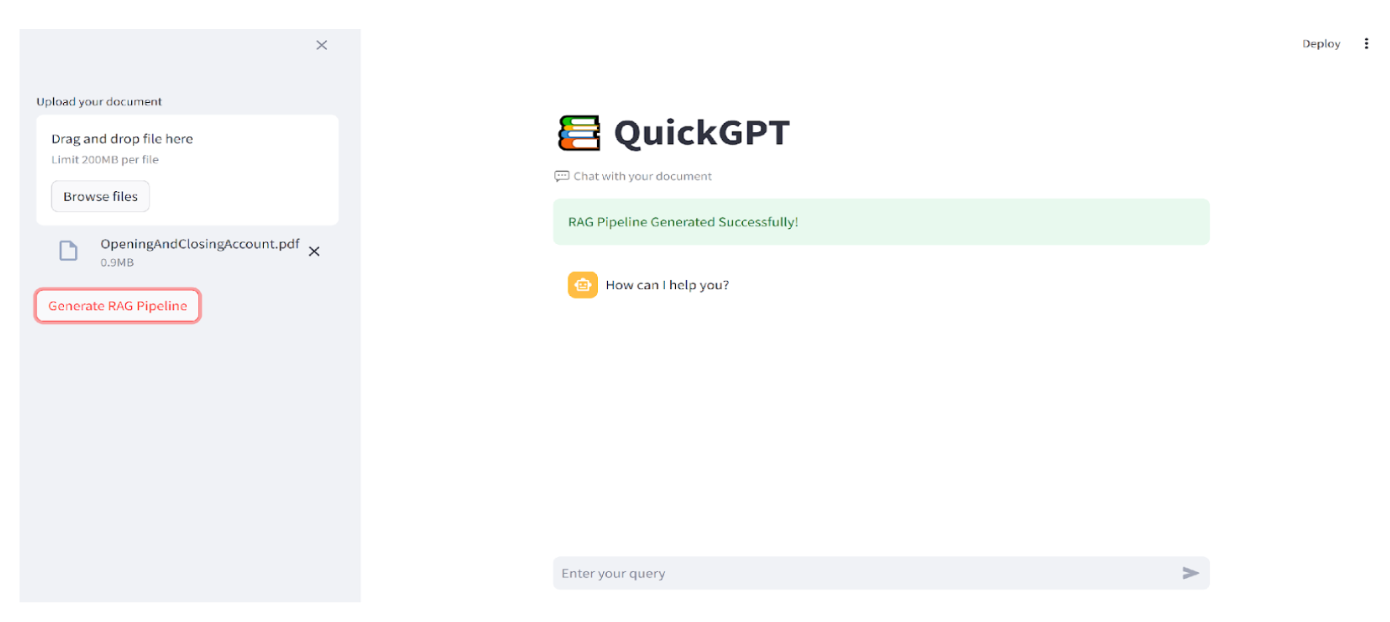
QuickGPT is a conversational document assistant that lets users upload PDFs and interact with them through natural language queries.
It addresses the challenge of extracting precise insights from large text collections by combining Large Language Models (LLMs) with Retrieval-Augmented Generation (RAG).
The result is a system that delivers context-aware answers quickly, reducing manual searching and making research, legal analysis, and reporting more efficient.
🛠 Tech Stack
- Core: Python, Streamlit
- LLM & Embeddings: Ollama with Microsoft’s phi-3 and Meta’s llama-3-8b model and snowflake-arctic-embed
- Retrieval: Qdrant (vector database)
- Architecture: Retrieval-Augmented Generation (RAG) pipeline
- Other Tools: Prompt engineering and fine-tuning
⚙️ How It Works
- Upload Documents: Users upload PDFs or text files through the Streamlit interface.
- Embedding & Storage: Documents are converted into vector embeddings using Ollama’s embedding models and stored in Qdrant.
- User Query: Users ask natural language questions in the chat UI.
- Retrieval: The RAG pipeline fetches the most relevant document chunks from Qdrant.
- LLM Response: The Ollama-powered LLM processes the query and retrieved context to generate accurate, context-specific answers.
- Output: Users receive responses directly in conversational format, eliminating the need for manual search.
🚀 Final Thoughts
QuickGPT streamlines information retrieval from large documents, making it useful for academia, law, medicine, and business. Its LLM + RAG architecture ensures fast, context-aware answers while maintaining strict document boundaries for accuracy.
By leveraging Ollama, Qdrant, and Streamlit, QuickGPT provides an intuitive way to “chat with your PDFs,” boosting productivity and accessibility across domains.